RuntimeErrorz
CV | FE
Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints
考古学家之点云配准
1. Contribution
- Imposing 3D constraints. 新颖的直接惩罚深度不一致的损失函数(直接比较公共参考帧中的三维点云来比较从相邻帧中提取的深度)。
- Principled masking. 场景的某些部分在新的视图中使用会降低效果,因此需要解析地计算masking。
- Learning from an uncalibrated video stream.(记录了一个新的数据集,其中包含骑自行车时使用手持商业手机相机拍摄的单目视频。只在这些视频上训练深度和自我运动模型,然后通过在KITTI数据集上测试训练好的模型来评估其预测的质量。)
2. Network
总览
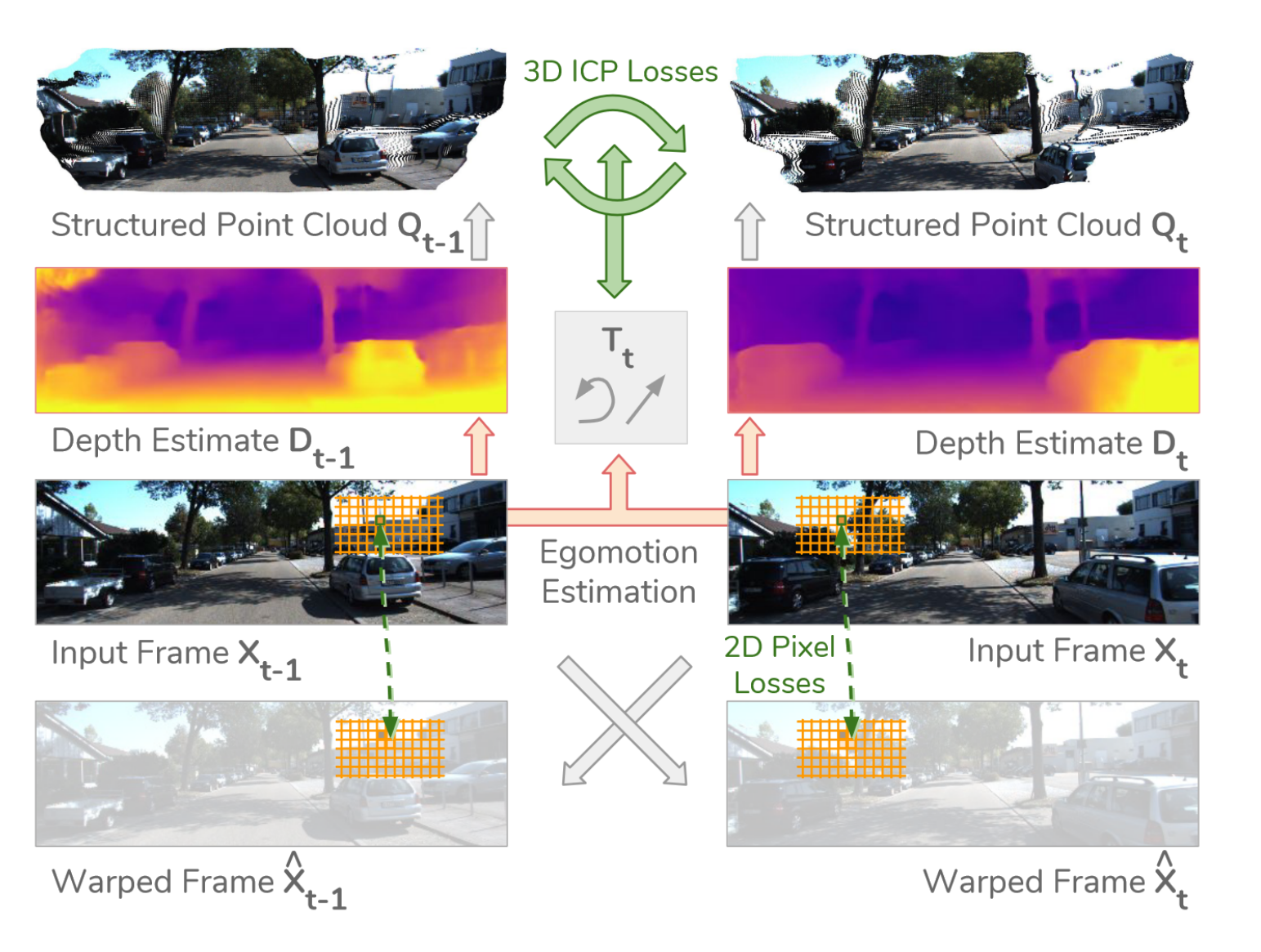
Principled Masks

原图和Warp后的图相减,剩下的超过了某一个阈值就mask掉,论文里面作为contribution的一点居然只字不提具体做法?ICP
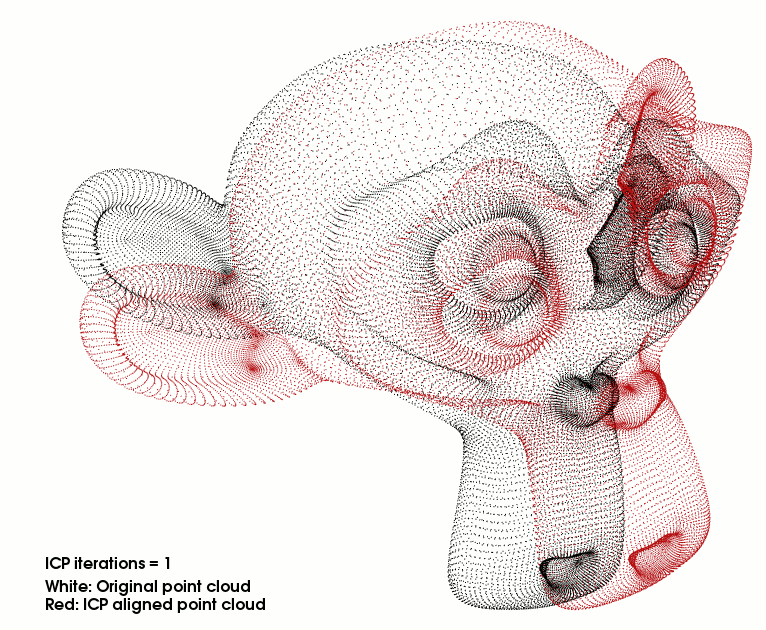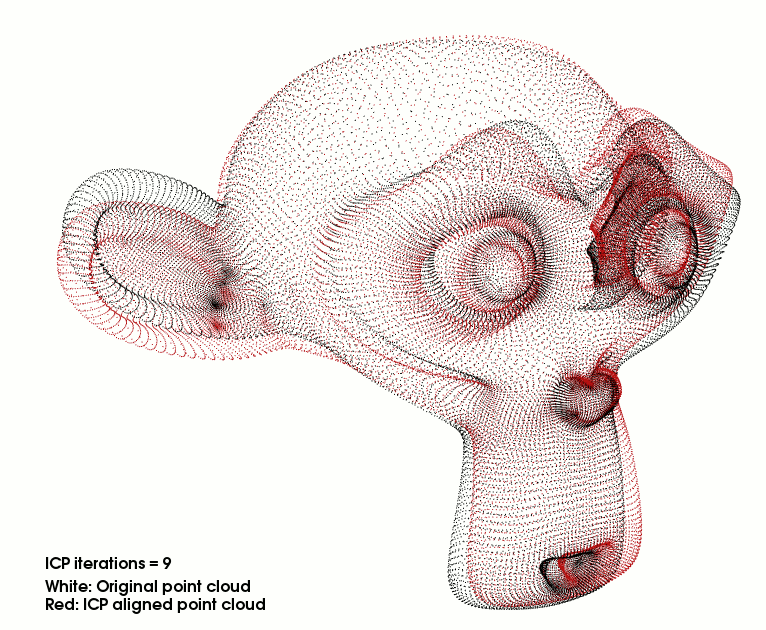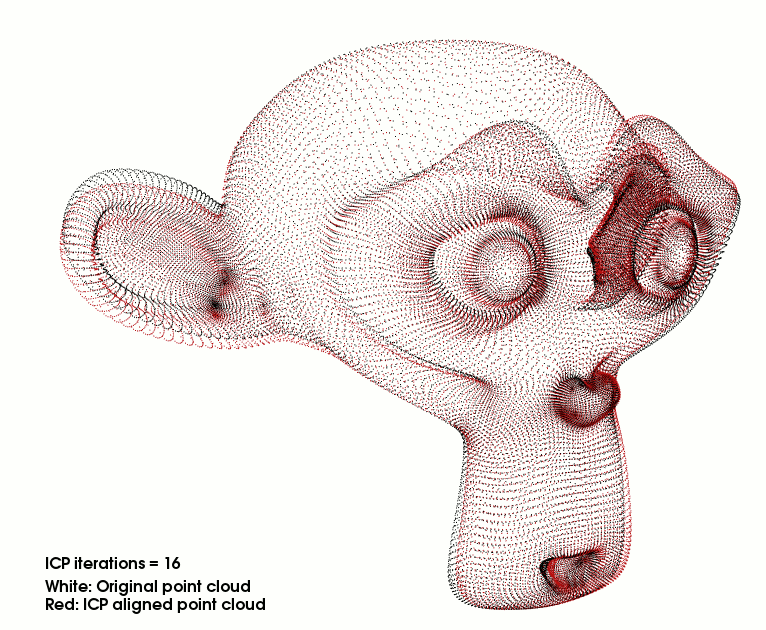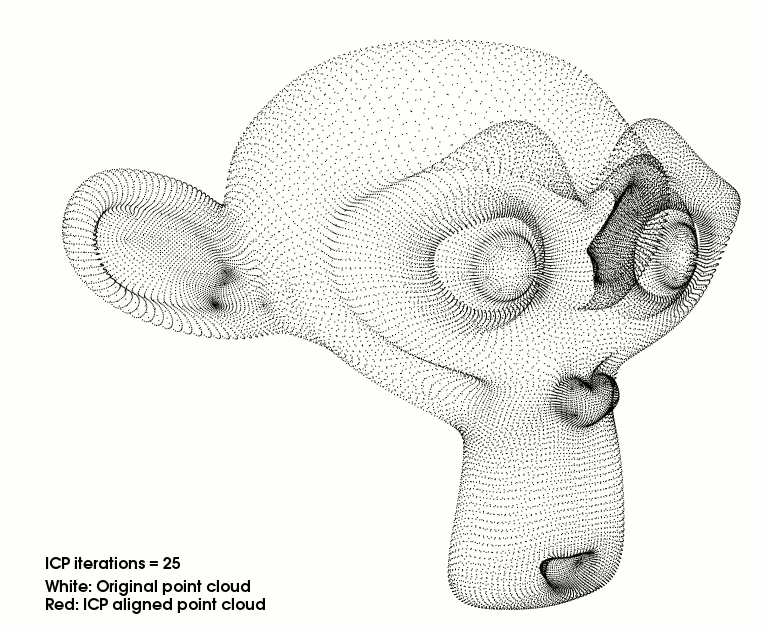
3D损失:在前向和后向对称地应用ICP,使连续两帧的深度和自运动估计一致。ICP的产品产生梯度,用于改进深度和自运动估计。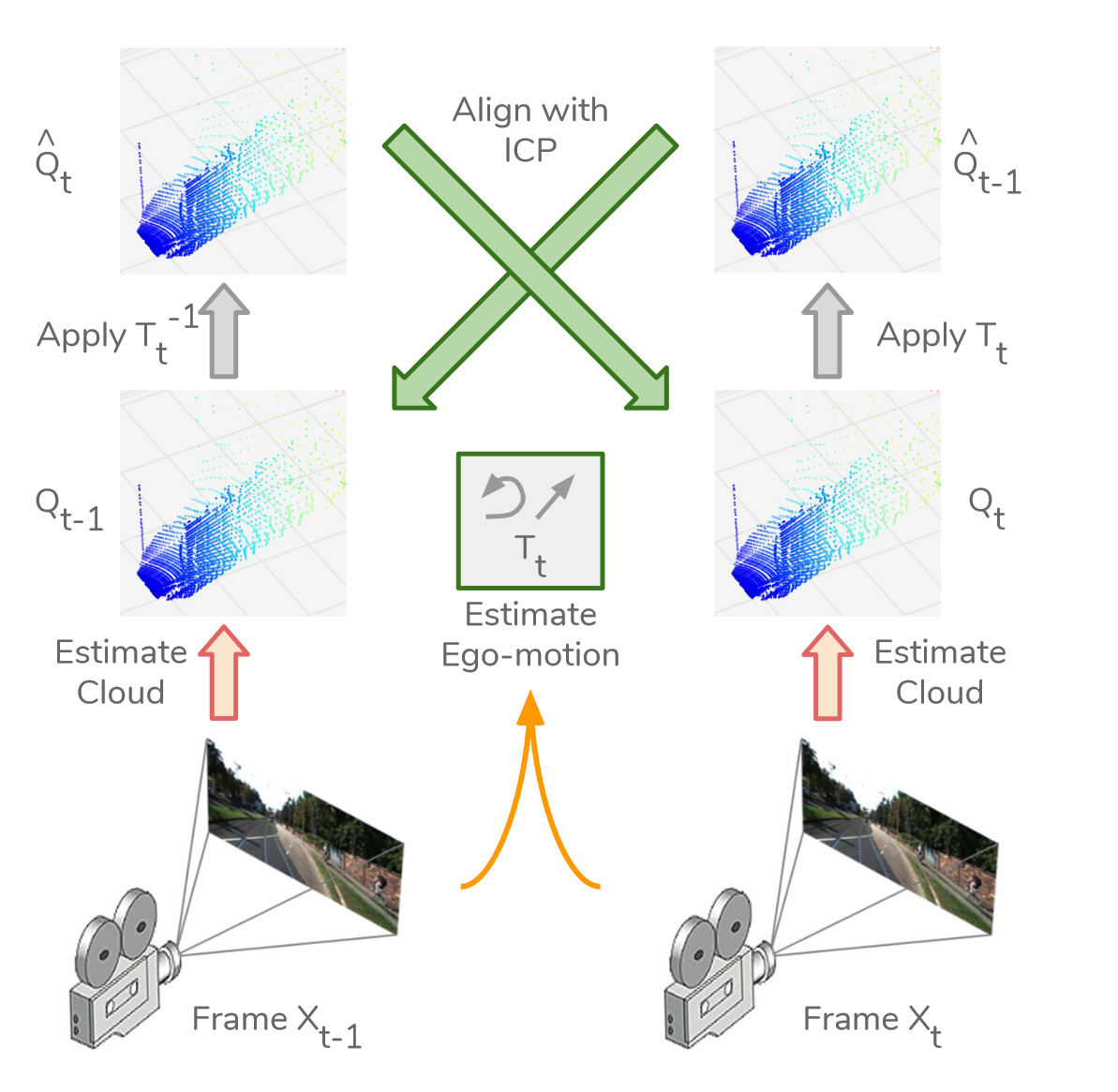
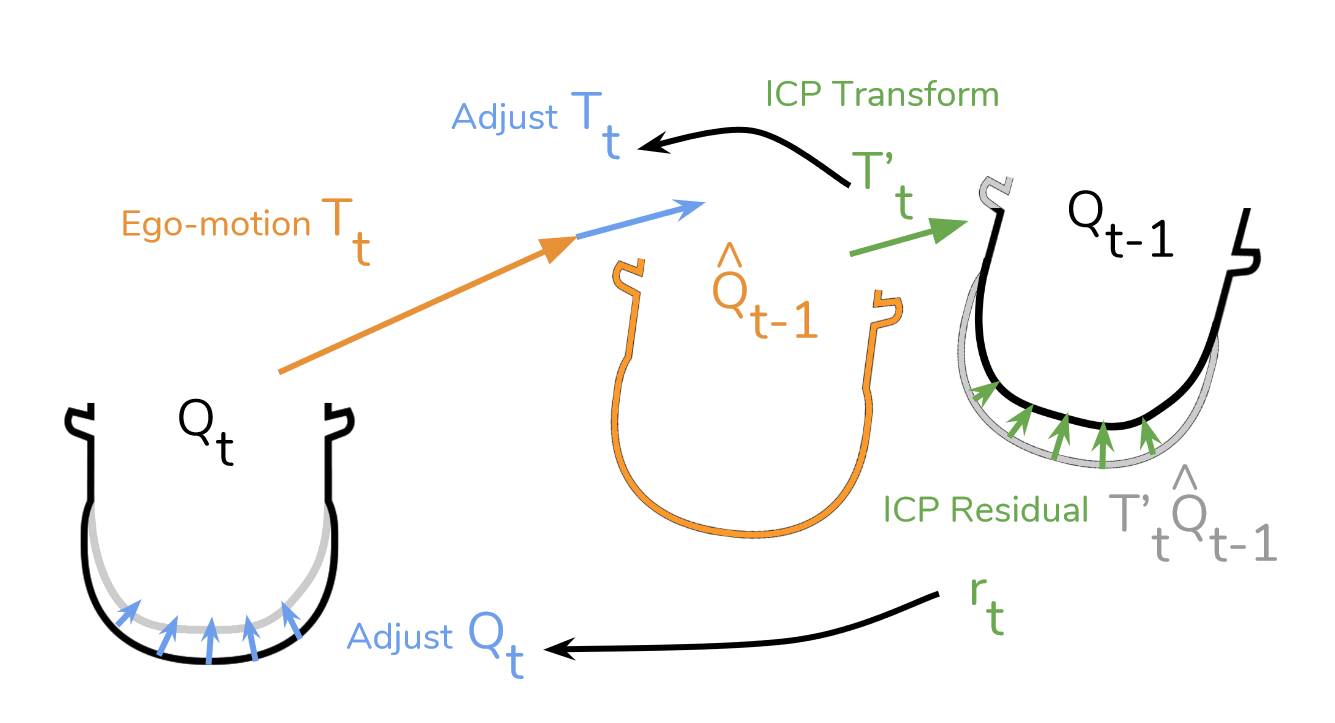
ICP经典点云配准:输入两个点云A,B,输出一个T’变换。让A->B的差距最小。c ( · )表示ICP找到的点对点对应
rij它反映了应用ICP的距离最小化变换后对应点之间的剩余距离如果神经网络对Tt和Dt的估计是完美的,则Qt - 1与Qt - 1完美对齐。当不是这种情况时,使用ICP将( Qt-1 to Qt-1 )对齐产生一个变换T′t和残差rt,该变换T′t和残差rt可以用来调整Tt和Dt以获得更好的初始对齐。更具体地说,我们使用T′t作为损耗关于自运动Tt4的负梯度的近似。为了校正深度图Dt,我们注意到即使在校正T′t之后,在rt方向上移动点也会减少损失(那就是本身的Dt不够准)。因此,我们使用rt作为损耗关于深度Dt的负梯度的近似。注意这种对梯度的近似忽略了深度误差对其的影响。
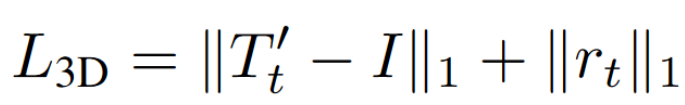
损失函数
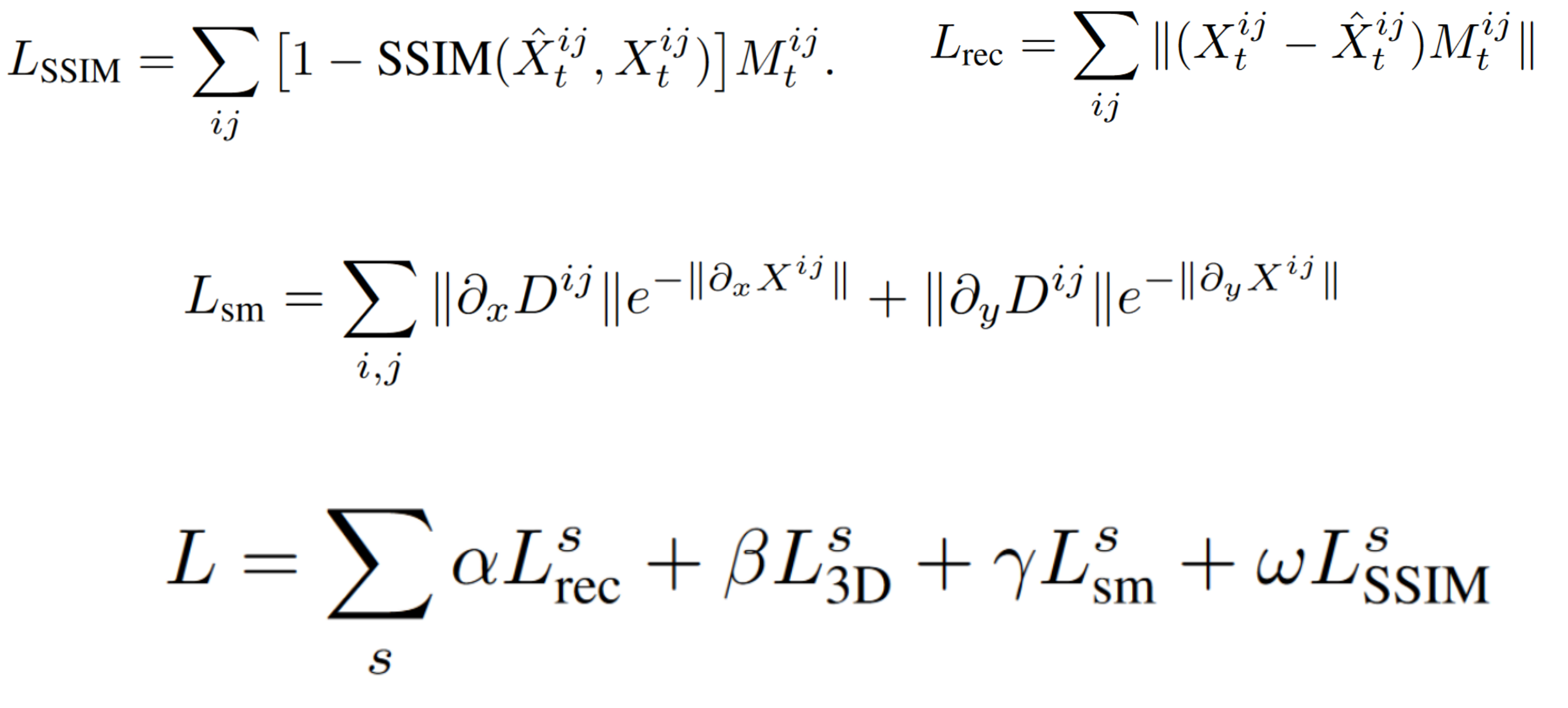 α = 0.85, β = 0.1, γ = 0.05, and ω = 0.15. 但是消融实验中ICP效果不如mask影响大?
α = 0.85, β = 0.1, γ = 0.05, and ω = 0.15. 但是消融实验中ICP效果不如mask影响大?