1. Contribution
一点凑了三个,笑嘻了。
- A Nover architecture: DepthFormer. 通过 Cross Attention和Self Attention 结合深度离散化对极采样改进多视图特征匹配。
- SOTA Results, 超过有监督的单帧架构
- Attention-based matching fuction is transferalbe across datasets.
2. Network
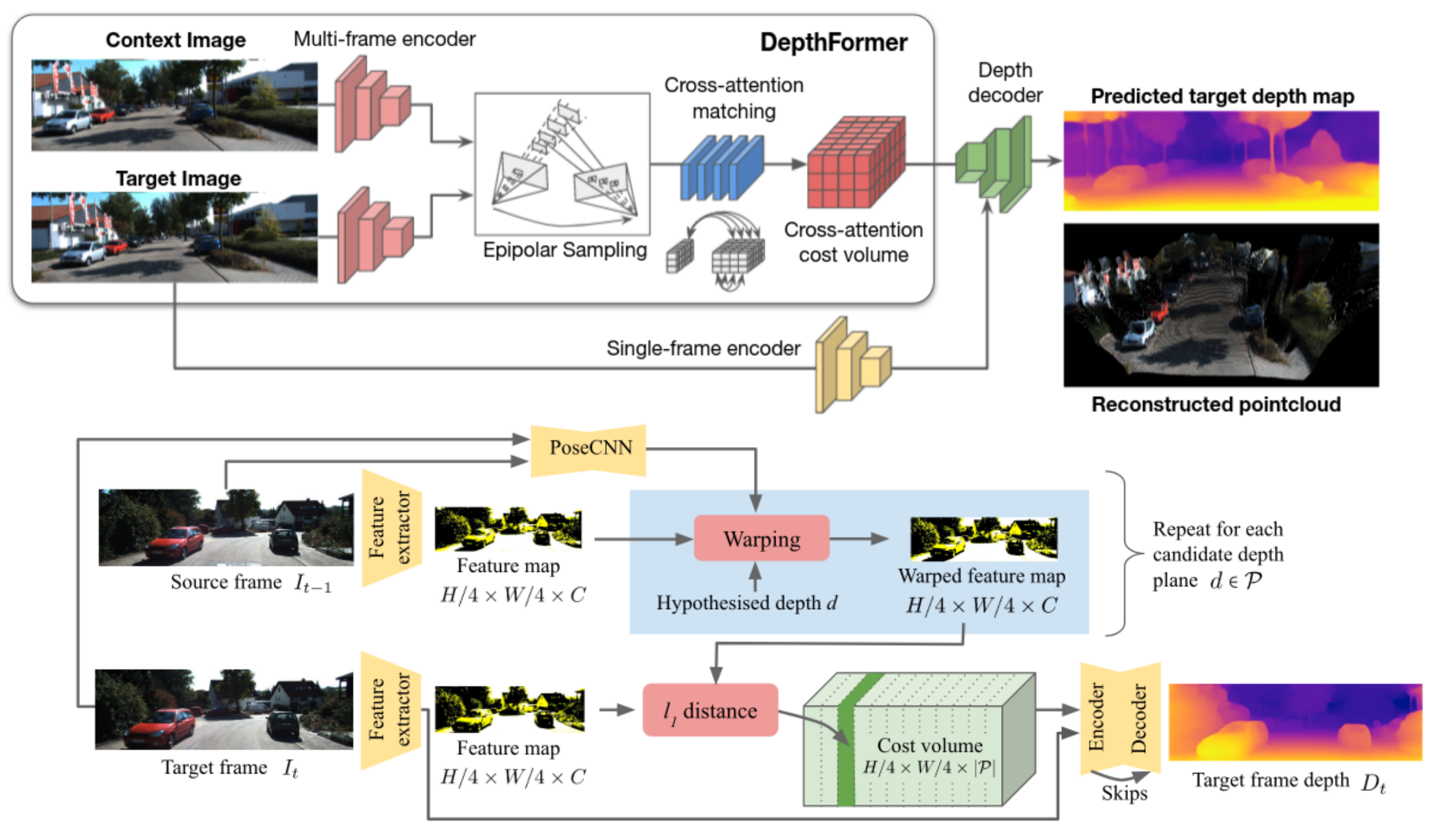
上图为本文的网络架构,下面的图是ManyDepth的网络架构。
可以看到整体结构还是比较相似的,在补充材料中也说了是C取的是t-1,ManyDepth还把PostCNN标注出来了。
不同的是:
- self-attention & cross attention交替优化cost volume;
- 使用high-response window解码深度,与传统的全局regress相比,这种方式可以避免multi-modal distributions对训练的干扰。
- context-adjust refinement:在最后的深度估计层,经过优化的cost volume特征与原图的RGB特征融合后一起解码深度信息。这可以增加深度的context信息。
Single-Frame Encoder的应用也是类似的。
2.1 CostVolume的生成:
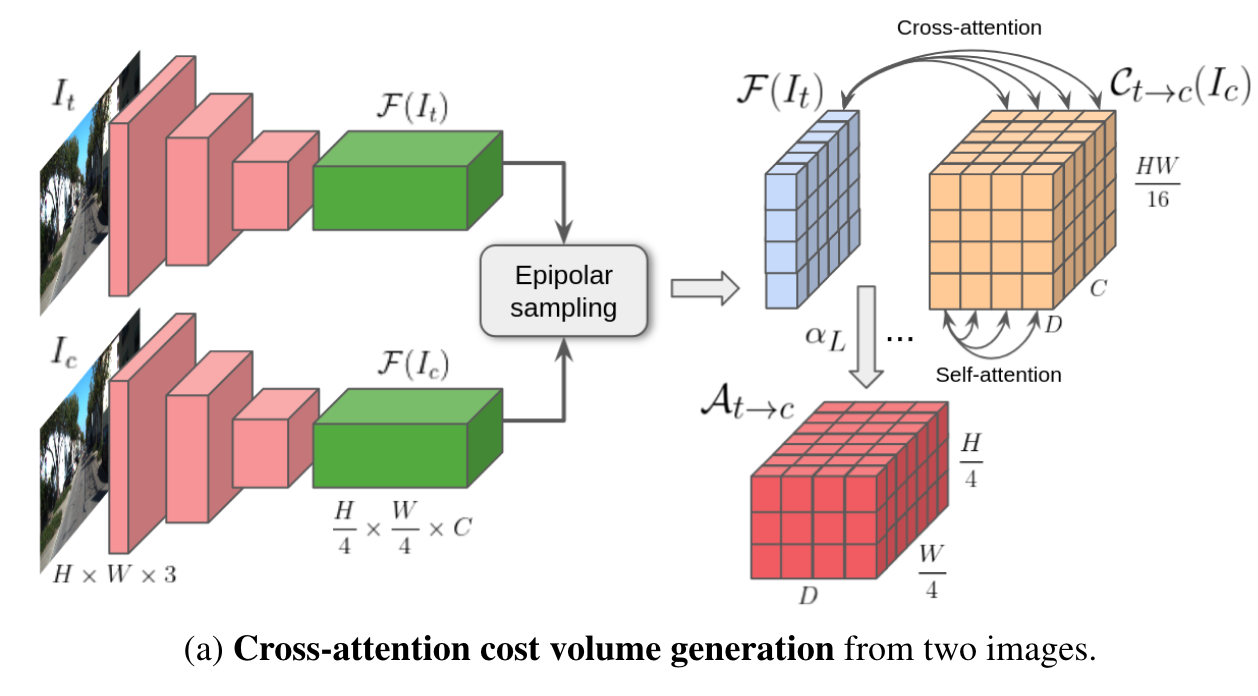
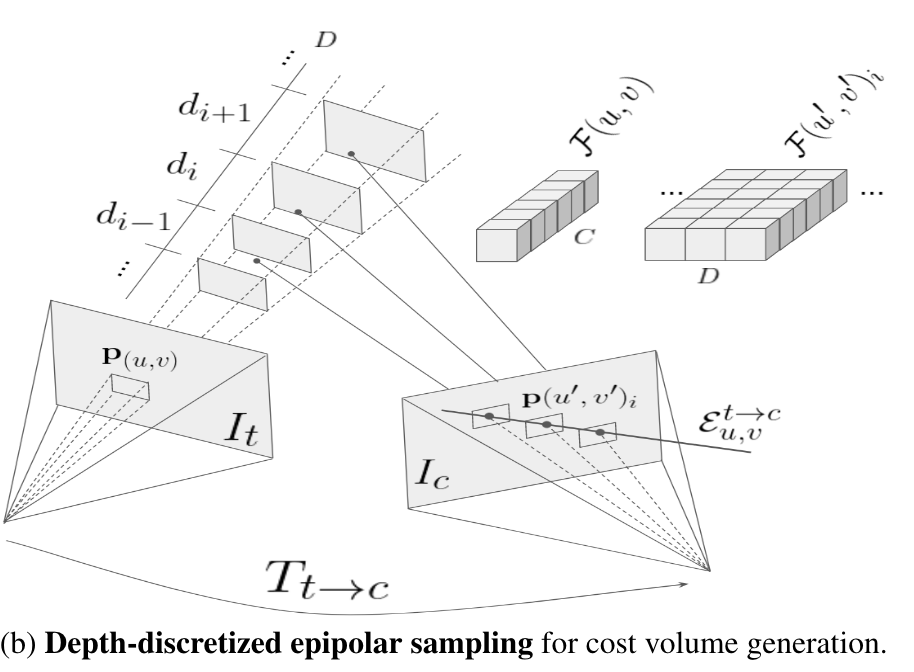
这里的epipolar sampling指的是,t上的一个点,对应了多种深度D,因此C_{t->c}的shape为:H/4W/4C*D,(这里的C其实是t-1)
最终的注意力值被用来填充交叉注意力成本量At→c,这是一个H/4×W/4×D的结构,编码Ft中的每个特征与其在Ct→c中的匹配候选人之间的相似度。
含义为:对于像素 (i, j),对于 P 中的每个 d,正确深度为 d 的可能性是多少
2.2 Cross-Attention Cost Volume的优势
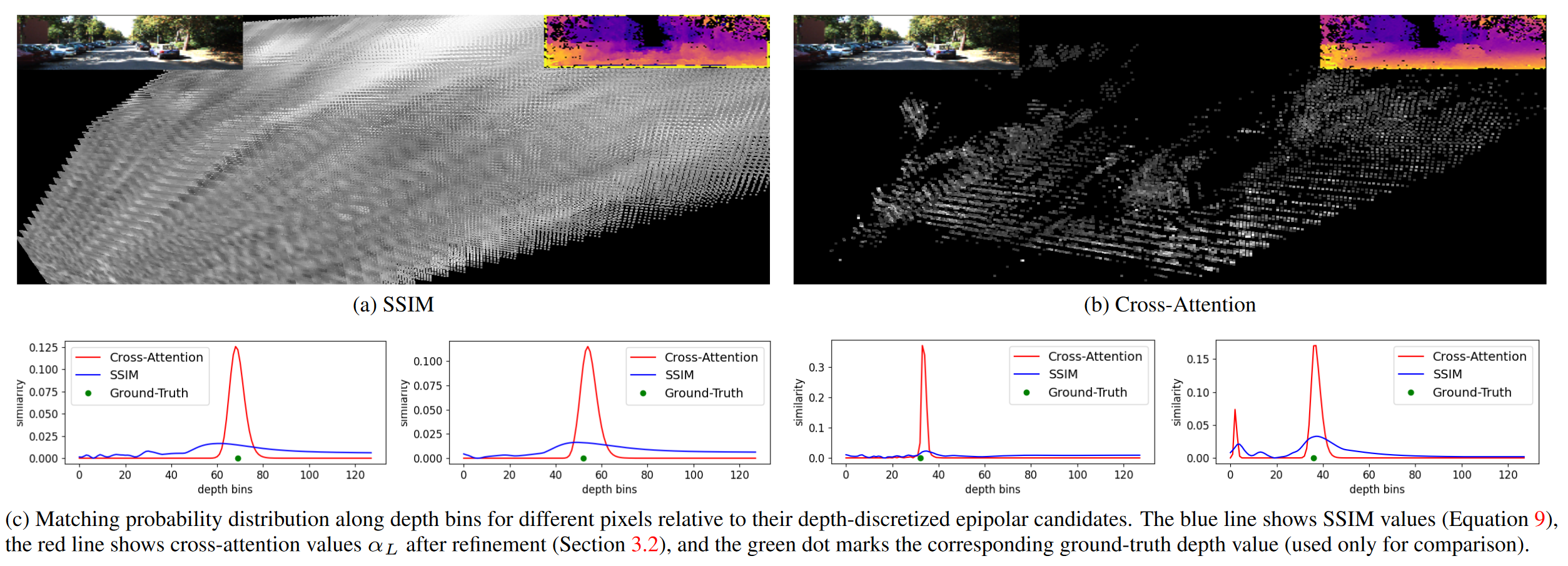
2.3 Cost Volume的解码
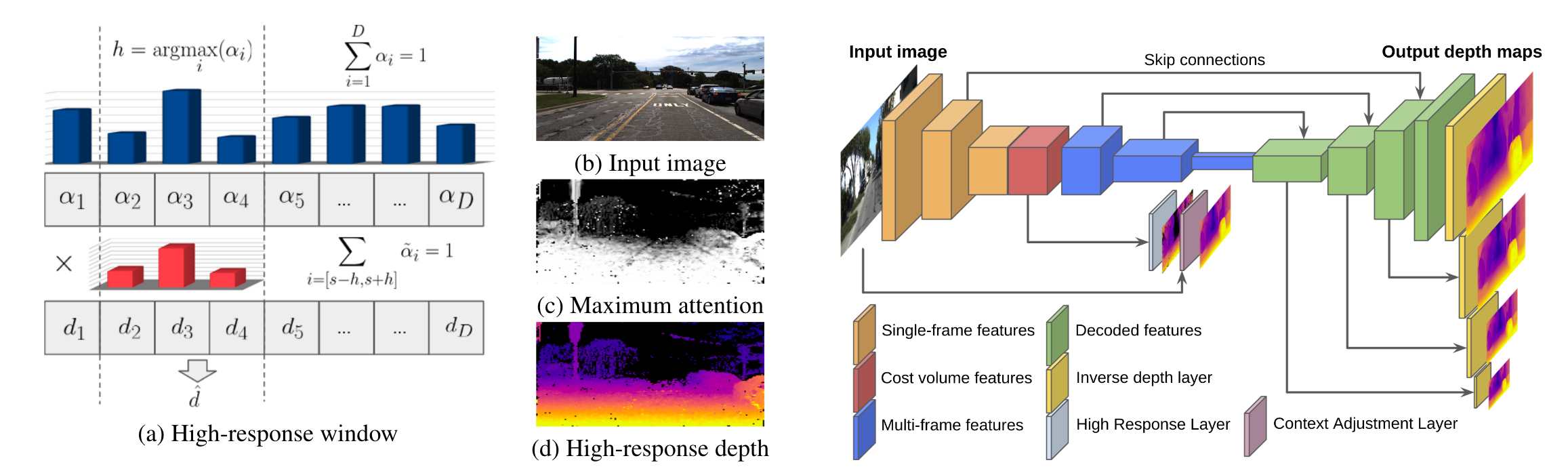
取平均值避免多峰分布。(ref中为:winner-take-all approach)
但是这样的深度缺乏上下文联系(交叉注意力成本量是在极线上进行回归的),所以采用了上下文调整层来细化深度值。context-adjust refinement:在最后的深度估计层,经过优化的cost volume特征与原图的RGB特征融合后一起解码深度信息。这可以增加深度的context信息。
Multi-Scale Depth Decoding(学习的ManyDepth):由于单目需要:1. 自我运动 2.静态世界的假设。本文采用了额外的单帧网络以用来补全成本量体积失败的地方,这个单帧网络采用共同的姿态预测网络,在评估的时候被丢弃。(ResNet18)
交叉注意力成本量(图 2a)首先被屏蔽掉,移除匹配置信度低的像素,然后与由单独网络编码的 It 中的单帧特征连接。瓶颈卷积层用于组合这两个特征图,并且输出被解码以在多个增加的分辨率下产生 S 深度估计。与 [83] 类似,我们使用师生训练程序,通过在成本量生成失败的区域监督单帧深度网络来提高多帧预测的性能。这个单帧深度网络是联合训练的,共享相同的姿势预测,并在评估期间被丢弃。
这个图画的似乎有些问题,没有交叉注意力成本量(图 2a)首先被屏蔽掉,移除匹配置信度低的像素,然后与由单独网络编码的 It 中的单帧特征连接。